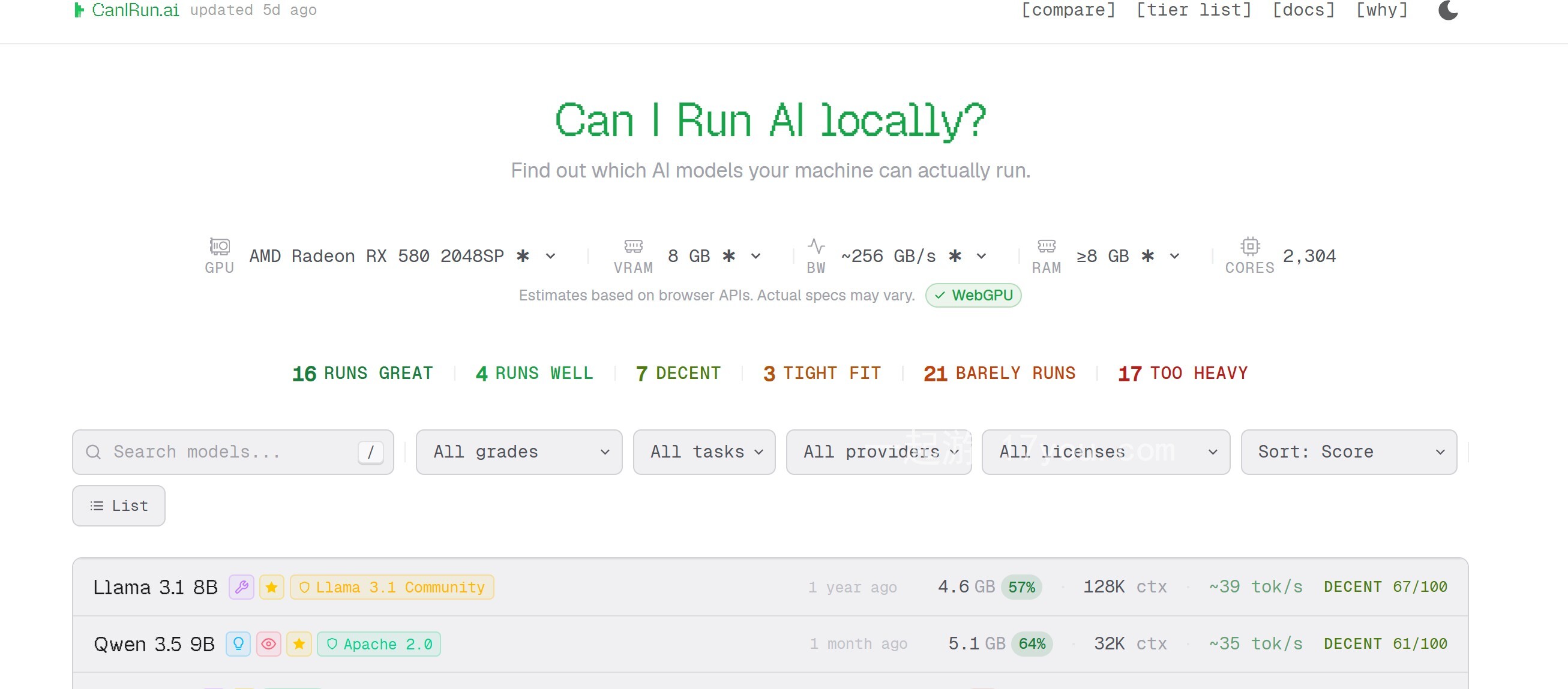
在线一键检测你的电脑能跑什么本地AI大模型 辉哥 发布于 2026-03-31 收录于 实用工具与脚本网页检测你的机器,能够运行哪些本地的 AI 模型。 一秒检测,你的电脑能跑什么本地 AI 模型? 无需下载,不用折腾,打开浏览器就能测。一键扫描你的硬件配置,智能匹配 Llama、Mistral、Gemma 等主流大模型,告诉你哪些能跑、哪些跑不动、哪些跑起来体验最佳。 本地 AI 的第一道门槛,我...
LLaMA-Factory零门槛操作的全能大模型微调平台 辉哥 发布于 2026-03-18 收录于 知识库图书馆在 LLM(大语言模型)微调领域,如果说 Unsloth 是追求极致速度的“轻量化跑车”,那么 LLaMA-Factory 就是一辆功能全、动力足、谁都能上手的“全能越野车”。 它是由北京大学团队主导开发的开源项目,目前已成为国内乃至全球最受欢迎的微调框架之一。以下是关于 LLaMA-Factory...
Unsloth开源AI模型训练框架本地加速大模型微调与推理 辉哥 发布于 2026-03-18 收录于 知识库图书馆Unsloth 是一个开源的本地化 AI 模型运行与训练工具,提供统一的界面(Unsloth Studio 网页 UI 和 Unsloth Core 代码库)来加载、微调和运行各类大型语言模型(如 Llama-3、Mistral、Gemma、Qwen 等)【39†L99-L105】【44†L313-...
Heretic:全自动移除LLM审查机制的开源工具,无需训练低成本对齐 辉哥 发布于 2026-03-16 收录于 编程技巧项目实战Heretic 全自动移除 transformer 架构语言模型审查机制(即“安全对齐”/censorship) 的工具,无需昂贵的模型后训练流程 ...
LLM量化等级全解析:如何根据显存选择最佳模型精度(Q8_0到Q2_K指南) 辉哥 发布于 2026-03-16 收录于 实用工具与脚本在 AI 模型(特别是大语言模型)中,量化等级(Quantization Level)指的是将模型权重从高精度浮点数(如 FP32)转换为低精度整数(如 INT8、INT4)的压缩程度。 它直接决定了模型文件的大小、运行速度以及推理质量。 简单来说: ...
OpenClaw对接本地Llama模型完整配置指南:Ubuntu与Win11详细教程 辉哥 发布于 2026-03-16 收录于 编程技巧项目实战OpenClaw 配置使用 llama.cpp 部署的本地模型 OpenClaw 可无缝对接 llama.cpp 部署的本地模型(HTTP 服务) 以下是针对 Ubuntu/Win11 系统的精准配置步骤,适配 llama.cpp b8370 版本。 ...
手把手教程:在Windows和Ubuntu上部署高性能本地AI大模型引擎llama.cpp 辉哥 发布于 2026-03-16 收录于 实用工具与脚本llama.cpp 是轻量级、高性能的本地 LLM 推理引擎,纯 C/C++ 实现,无冗余依赖,支持 GGUF 模型量化、多硬件加速(CPU/GPU)、多模态推理,是本地部署翻译 / 对话类 LLM 的核心工具。 ...
传统 AI 搜索的幻觉困境与治理路径 辉哥 发布于 2026-03-01 收录于 AI 智能体实践在人工智能飞速发展的今天,传统AI搜索面临着幻觉困境和数据非确定性的双重挑战 传统AI搜索的幻觉困境 深度解析大语言模型的虚假信息生成机制及其对用户信任的系统性破坏 ...
检测本地硬件适配大模型LLM 辉哥 发布于 2026-02-22 收录于 实用工具与脚本检测本地用户硬件配置(CPU、RAM、GPU),匹配适配的能流畅运行的本地大语言模型(LLM),目前已收录157个模型、支持30家提供商 ...